
Top 15 Algorithms Every Software Engineer Must Know
1. Overview
Developers and software engineers preparing for an interview might need to refresh their memory on two topics:
This article will examine some of the most popular algorithms in software programming. The algorithms are grouped according to their functionality. Five groups have been defined: sorting, searching, graph, arrays, and a general category for those algorithms that did not fit in any of the previous four.
We will also examine each algorithm’s time complexity or the time it needs to complete its execution as a function of its number of inputs. We will use the Big O notation to measure time complexity.
2. Algorithmic Time Complexity
2.1 Algorithmic Time Complexity
Time complexity allows us to measure and compare the efficiency of a specific algorithm. It works as follows:
2.2 Big O Notation
We use the Big O Notation (invented by Paul Bachmann, Edmund Landau, and others, referred to as Bachmann–Landau or asymptotic notation) to classify algorithms according to their speed concerning their input size, as the latter tends towards infinity. The asymptotic nature of this measure is essential since, for small input size values, the choice of which algorithm to use may not matter. Therefore, we want to compare speeds at high values only.
To see how this works, let’s assume that you have calculated the number of operations to be performed and you got the following formula:

As N approaches infinity, the dominant term in this equation will be 

Several complexity classes exist; we will consider three to illustrate how this works.
2.3 Problems Solvable in Polynomial Time (P)
P represents the class of decision problems solvable in polynomial time, or:

This class of problems is what we hope for as it’s the easiest to solve on classical computers.
2.4 Problems Solvable in Exponential Time (EXP)
EXP includes the set of decision problems solvable in exponential time, or:

This class of problems is hard to solve on classical computers, but algorithms may exist that can solve them in polynomial time on quantum computers (Shor’s factoring algorithm).
2.5 Problems Solvable in Finite Time (R)
R represents all problems solvable in finite time. P, EXP, and R classes include a tiny fraction of all existing problems; most decision problems have no solution (see this lecture).
3. Searching Algorithms
The objective of the search algorithm is to examine an array of values and attempt to locate the position (or index) of the desired value within the list at optimal speed.
3.1 Linear Search
Problem Description — Given a random and unsorted array of N elements, the algorithm must return the index of a value x in the array.
The most trivial of all search algorithms is the Linear Search, in which the program performs an exhaustive search over all array values, one by one until it finds what it’s looking for.

Linear Search Complexity — The Linear Search algorithm will inspect, on average, half the number of values in an array and, at worst, all values. Its computational complexity is O(N).
3.2 Binary Search
Problem Description — Given a randomly sorted array of N elements, the algorithm must return the index of a value x in the array.
Binary Search leverages the array’s sorted order to narrow its search space in a divide-and-conquer manner. It works as follows:
- Step 1 — Inspect the middle element of the array and compare it to the one we are searching for.
- Step 2 — If it matches, the algorithm returns this value and stops.
- Step 3 — Otherwise:
- If the value is smaller, repeat Step 1 on the right half.
- Otherwise, repeat Step 1 on the left half.

Binary Search Complexity — In the worst scenario, the Binary Search algorithm must divide the array in half k times. If the array length is:

Then

And therefore, its time computational complexity is:

3.3 Grover’s Algorithm
Problem Description — Grover’s algorithm tries to solve the same search problem we have seen so far in an array of unsorted N elements, except that its approach is radically different. In this scenario, we have a quantum processor and use a quantum algorithm to run the search for us.
A brute-force search method is our only option for an unsorted array, and the resulting time complexity on a classical system is O(N).
By leveraging quantum superposition, entanglement, and interference, we can reduce the computational complexity to 

To achieve this remarkable result, we must first reformulate the problem as a black box with an “oracle” inside. The black box is not a classical system but a quantum one.
Whenever we query the “oracle”, we get a binary answer. The query runs as follows: “Is the number in the box 15?”. If the black box contains the queried number, the answer is true; otherwise, it’s false.
In summary, Grover’s quantum algorithm works as follows:
- Step 1 — We create enough qubits to cover the possible range of numbers the box might contain.
- For example, if the hidden number is [0-8], we need
, i.e. three qubits.
- For example, if the hidden number is [0-8], we need
- Step 2 — We use Hadamard gates (the quantum analogues of boolean or logical gates of the classical system) to create a quantum superposition of all qubits.
- This superposition will allow us to calculate all possible input values in one shot! Instead of three qubits, we have a single quantum input system composed of the superposition of all possible values that the three qubits can take (000, 001, 010, 011…).
- Step 3 — We run the input through a Controlled-Z gate, the latter simulating our oracle. A Controlled-Z gate will flip the sign of the input if it’s (1, 1) and leave the input unchanged otherwise. As such, our hidden number is (1, 1).
- Step 4 — Because this is a quantum system, we might get any answer when we perform our measurement at the end, except that the correct answer (1, 1) has a slightly higher probability of turning up when we measure the output qubits.
- Step 5 — Now, we have two options. We run the calculation multiple times and take a majority vote, or we use an amplitude amplifier (called a reflection operator) that amplifies the probabilities such that the most likely result will have a much higher chance of turning up in the first run.
Grover’s Algorithm Complexity—The probability of measuring the correct answer after applying the quantum gates in Grover’s algorithm depends on the angle separating the desired state from the output state; the smaller the angle, the higher the chance.
This angle closes between the two state vectors as more iterations of the amplitude amplifier are applied. It has been shown that the optimal number of iterations is in the order of
4. Sorting Algorithms
Problem Description—Sorting algorithms rearrange the elements of an array of N random numbers in ascending order. Several algorithms compete for the lowest runtime and memory usage complexity.
4.1 Insertion Sort
Insertion sort is an intuitive yet costly sorting algorithm, and it works by running up to N passes over the entire array.

The algorithm will inspect the elements from 1 to N on each pass and compare them to the one on their left. If the number is smaller than its left neighbour, they are swapped. This comparison and switching move in a leftward direction like a wave, stopping only when the number on the right is greater than its left.
Insertion Sort Complexity — The time complexity of the insertion sort is 
4.2 Merge Sort
Merge sort works by recursively looking at two-element adjacent subarrays from left to right. Elements 1-2 would first be sorted before moving to 3-4. Next, elements 1-2-3-4 would be sorted before adding 5-6. The sorting continues in this manner till the end of the array is reached.

Merge Sort Complexity — The time complexity of the merge sort is O(N log{N}).

The divide and conquer step recursively sorts two subarrays whose length ranges from 

The merge step merges N elements, thereby incurring a cost of 

4.3 Quicksort
The quicksort algorithm was developed in 1959 by Tony Hoare (paper) while working on a machine translation project for the National Physical Laboratory. He needed to sort the words in Russian sentences before looking them up in a Russian-English dictionary. He realized that an insertion sort would not be the fastest method and, therefore, had to develop a new one, later becoming standardized as Quicksort.
Quicksort is yet another divide-and-conquer algorithm that uses the notion of a pivot. The latter is an element in the array (typically the last). It works as follows:
Quicksort Complexity — The time complexity of Quicksort is sensitive to the choice of the pivot; for example, if the array is already sorted and the pivot is chosen as the last element, the algorithm will need to inspect all the subarrays 
Several Quicksort variants exist to minimize the algorithm’s sensitivity to the choice of the pivot.
The time complexity of the merge sort is
5. Graph Algorithms
A graph is defined by its edges and vertices G = {V, E}. Edges can be weighted with negative and positive numbers representing the “cost” of moving along that edge. They can also have a direction.

5.1 Kruskal’s Algorithm
Problem Description — Given a graph G = {V, E} with V vertices and E weighted, non-negative edges, find a minimum spanning tree within G. A minimum spanning tree is a graph containing all the vertices in G and a subset of the edges E. The sum of the weights of the included edges must be minimized.
To find the minimum spanning tree, Kruskal proposed the following algorithm in this paper:
- Step 1 — Make a list of all the edges sorted in ascending order of their weights.
- Step 2 — Add the topmost edge and vertices to the minimum spanning tree.
- Step 3 — Iterate through the list and inspect the vertices of the candidate edge:
- If they are already in the target tree, move to the next item on the list to avoid creating a cycle.
- Otherwise, add the edge.

Because the selection algorithm might have to choose between two equally weighted edges in the greedy addition process, multiple spanning trees with minimum costs can be found.
Kruskal’s Algorithm Complexity — Kruskal’s algorithm runs in 


In sparse graphs (least complexity), we have:

In dense graphs (worst complexity), we have:

Therefore, when considering the worst-case scenario:


Leading to

5.2 Dijkstra’s Algorithm
Problem Description — Given a graph G = {V, E} with V vertices and E weighted, non-negative edges, find the shortest path between two designated vertices, S and E.
The first algorithm that comes to mind is to perform an exhaustive search of all the different paths from S to E, which requires building a tree with a S root node and leaves E.

This search strategy is suboptimal as it does not consider the information we accumulate as we search through the branches. For example, if we have two paths, P1 and P2, joining vertices Start and A, where the cost of P1 is 11 while that of P2 is 15, we can immediately infer that any path that uses P2 is suboptimal to any path that uses P1, and, therefore, there is no need to explore those with P2.

Dijkstra’s algorithm (original paper) records the best route between S and every other vertex in G to take advantage of this knowledge. It also uses a greedy approach to determine the shortest path between S and E.
Dijkstra’s algorithm runs several iterations on the graph. Each new iteration explores the adjacent nodes reachable from the previous round while keeping track (typically in a table) of the shortest distance between S and those examined nodes. If a shorter path is located, it updates the tracking table and uses the new paths in the next iteration.
- Step 1 — Initialize all distances (except the Start node) to infinity,
. Complexity is
.
- Step 2 — Maintain an exclusion list, initially empty. Complexity is
.
- Step 3 — Select the node with minimum cost
and not in the excluded list, complexity is
- Add
to an exclusion list so that we do not revisit it in the next round, in
- “Relax” all the adjacent nodes by finding the shortest distance between the current node
.
- If there is a shorter distance to vertex
, update
, in
.
- Repeat Step 3 until all nodes are in the exclusion list.
- Add
Dijkstra’s Algorithm Complexity—Dijkstra’s algorithm must relax all V nodes in E iterations, leading to a complexity of 
This order, however, can be improved by:
- Using a priority queue so, instead of having to search all V elements to find the minimum cost, we pop the first item in
- Using an adjacency list instead of a V x V matrix.

The time complexity of Dijkstra’s algorithm would then be O(E x log(V)).
5.3 Bellman-Ford’s Algorithm
Problem description — One of the drawbacks of Dijkstra’s algorithm is that it cannot handle negative weights in edges (more specifically, Dijkstra’s algorithm cannot avoid being trapped in a negative cycle of ever-decreasing cost); this is where Bellman-Ford’s algorithm steps in, which also determines the shortest path from a single source in a graph.
Check the graph below to understand what a negative cycle is.

The Bellman-Ford algorithm works like this:
- Step 1 — Initialize all distances (except the Start node) to infinity,
. Time complexity is in
.
- Step 2 — Loop
times, complexity in
:
- Iterate through all the edges
. Here the complexity is
- If there is a shorter distance to vertex
through
, complexity in
- If there is a shorter distance to vertex
- Iterate through all the edges
Bellman-Ford’s Algorithm Complexity — Bellman-Ford’s updates all edges 

Negative Cycle Test — A negative cycle exists within a graph if the shortest route from Start to End decreases after
6. Array Algorithms
6.1 Kadane’s Algorithm
Problem Description — Given an array of numbers ![A[1..n]](https://s0.wp.com/latex.php?latex=A%5B1..n%5D+&bg=ffffff&fg=000&s=1&c=20201002)

Ulf Grenander initially proposed the problem in 1977 while looking for a rectangular subarray with a maximum sum in a two-dimensional array of real numbers.
A brute-force approach would calculate the sum of all subarrays whose lengths start from 1 to 
![[2,3]](https://s0.wp.com/latex.php?latex=%5B2%2C3%5D+&bg=ffffff&fg=000&s=1&c=20201002)


A modified version of Kadane’s original algorithm solves the abovementioned problem, i.e. including positive and negative numbers. It works as follows.
# Find the subarray with the largest sum
def find_max_subarray(arr):
# Starting from -inf will allow us to deal with
# negative numbers
max_sum = float('-inf')
# A local sum will allow us to keep track of the best
# candidate encountered so far
local_sum = 0
# Loop once through all elements
for x in arr:
# If the new element is greated than the local sum,
# we start a new subarry. This makes sense when the
# local_sum is negative
local_sum = max(x, local_sum + x)
# Keep track of the best sum achieved so far
max_sum = max(max_sum, local_sum)
return max_sum
We can see that algorithm at work in the following example.

Kadane’s Algorithm Time Complexity — This algorithm iterates through all the elements in the subarray and has a complexity of 
6.2 Floyd’s Cycle Detection Algorithm
Problem Description — Given a finite set 

One application of cycle detection is in measuring the strength of a pseudorandom number generator; better generators have larger cycles. Another application lies in the detection of infinite loops in computer programs.
Below is an example of a finite set and a function 

Floyd’s algorithm works by tracking two pointers, A and B. On every iteration, pointer A advances one step while B advances two. Once they get on the cycle, it’s only a matter of time before both pointers meet, and a test of their meeting point would determine the presence of the cycle.
The algorithm requires a function f and starting point s0; it looks as follows.
def floyd_detector(f, s0):
# The hare and toroise is an allusion to Aesop's fable
# of The Tortoise and the Hare.
tortoise = f(s0) # f(s0) is the next element
hare = f(f(s0)) # f(f(s0)) is the element after the next
while tortoise != hare:
# If the hare hits the null pointer, no cycles exist
if hare == null:
return 0
tortoise = f(tortoise)
hare = f(f(hare))
return 1
The algorithm above works only if the graph is linear (no cycles) or looks like the Greek letter 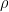
6.3 Knuth–Morris–Pratt (KMP) Algorithm
Problem Description — Given a string ![s[n]](https://s0.wp.com/latex.php?latex=s%5Bn%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![w[m]](https://s0.wp.com/latex.php?latex=w%5Bm%5D+&bg=ffffff&fg=000&s=0&c=20201002)

As always, it’s beneficial to consider the pros and cons of the brute-force approach before looking for potential enhancements and optimizations. The brute-force approach would look like this.
def naive_search(s, w):
m = size(w)
n = size(s)
# Starting with the first character in s, compare all
# elements of s with the first character in w
i = 0
while i < (n-m):
j = 0
while 1:
# If the characters match, check the next
if s[i] == w[j]:
j += 1
i += 1
# Otherwise, move to the next in s
else:
i += 1
break
# If we got to m, we have a match
if j == m:
return 1
return 1
Assuming that s is entirely random, the probability of matching the first character is 1/26, while that of the second would be 1/676 (characters in s are [a-z] only). It is safe to say that, on average, n comparisons will be made, and then the time complexity of the naive approach is no more than
That, however, is the best scenario. At the same time, the worst would be for the naive search algorithm to match many characters from m before dropping off the last characters and restarting again (see the example below).
The brute force method’s time complexity would then become 
A simple trick to optimize our search would be to jump 
- s = AAAAZAAAAAAAAAAAAAA
- w = AAAZ
The Knuth–Morris–Pratt (KMP) algorithm avoids this trap while achieving a better result (in
Instead of jumping four characters and missing the match, a table T will be maintained, storing static information on how far back we have to go when a mismatch occurs. Instead of jumping 
![m-j-T[i]](https://s0.wp.com/latex.php?latex=m-j-T%5Bi%5D+&bg=ffffff&fg=000&s=0&c=20201002)
The details of how T is populated are tedious, and we won’t discuss them in this article. However, the final algorithm looks like this:
def kmp_search(s, w):
m = size(w)
n = size(s)
# Starting with the first character in s, compare all
# elements of s with the first character in w
i = 0
j = 0
T = calculate(w) # Our backtracking table
while i < (n-m):
# If the characters match, check the next
if s[i] == w[j]:
j += 1
i += 1
else:
j = T[j]
if j < 0:
j += 1
i += 1
# If we got to m, we have a match
if j == m:
return 1
return 1
6.4 Boyer–Moore Majority Vote
Problem Description — Given an array of elements, find the majority value of that array.
Let’s take the below example:
Boyer–Moore majority vote algorithm maintains a counter and variable iterating through the sequence.
The variable holds the current majority winner, while the counter stores the number of occurrences. The below code shows how it works.
def boyer_moore_majority(s):
cnt = 0
var = ' '
for k in 1..size(s):
if cnt == 0:
cnt = 1
var = s[k]
else:
cnt -= 1
To illustrate how it works, the table below shows the iterations for the example above:
| s[k] | Counter | Variable |
|---|---|---|
| – | 0 | – |
| A | 1 | A |
| A | 2 | A |
| B | 1 | A |
| C | 0 | A |
| changing to 1 | A replaced with C | |
| D | 0 | C |
| 1 | C replaced with D | |
| C | 0 | D |
| 1 | D replaced with C | |
| C | 2 | C |
| A | 1 | C |
| C | 2 | C |
| C | 3 | C |
7. Miscellaneous
7.1 Huffman Coding Compression
Problem Description — Given a string of characters, create a compressed, lossless version of that string.
Computers in the 1950s were very short on disk space, and compression algorithms of sizeable text files made storage more efficient. The compression had to be lossless since, unlike images, a lossy compression might render the text erroneous or unusable.
David Huffman solved the lossless compression problem in 1952. His method, subsequently known as Huffman Encoding, was described in a report to the IRE. It worked as follows. ASCII characters are stored in eight bits, and Huffman’s idea was to design an encoding algorithm that would allow the same amount of information to be stored in shorter code. The repetition of some characters in the text facilitates this shortening of the representation. Let’s look at the below example:
Huffman’s algorithm proposed generating a tree that uniquely encoded each character; characters that appeared more frequently in the text (like ‘A’ in the above string) were mapped to codes with fewer bits than eight. Characters that appeared less often, like the ‘D’ in the above example, were mapped to longer codes.
The Huffman code is constructed by ordering the letters by occurrence in the text:
| Character | Occurrence | Tree Level 1 | Tree Level 2 | Tree Level 3 | Final Code |
|---|---|---|---|---|---|
| A | 10 | 0 | 0 | ||
| C | 5 | 0 | 1 | 10 | |
| B | 4 | 0 | 1 | 110 | |
| D | 1 | 1 | 111 |
The original message was 20 x 8 bits = 160 bits long, while the compressed message (excluding the size of the mapping table) is (10 x 1) + (5 x 2) + (4 x 3) + (1 x 3) = 35, an impressive reduction of 78%.
7.2 Euclid’s Algorithm
Problem Description — Given two natural numbers, a and b, find their greatest common divisor or gcd.
Euclid tackled this problem around 300 BC and included the solution in his book Elements. He figured out that if two natural numbers, a and b, share a greatest common divisor, d, then d is also the gcd of b and r, where r is the remainder of the division of a by b.
If

Then

The proof can be done in a few easy steps. If:

Then


But

And therefore:
The algorithm works by starting with two large numbers, a and b, and recursively:
- Finding q and r such that
- Then applying
and


The algorithm stops when a or b is either one or zero, as shown in the below example.
| a | b | Step |
|---|---|---|
| 1,771 | 989 | 1,771 = 1 x 989 + 782 |
| 989 | 782 | 989 = 1 x 782 + 207 |
| 782 | 207 | 782 = 3 x 207 + 161 |
| 207 | 161 | 207 = 1 x 161 + 46 |
| 161 | 46 | 161 = 3 x 46 + 23 |
| 46 | 23 | 46 = 2 x 23 |
| 23 | 0 | GCD is 23 |
8. Final Words
Operational Excellence, the theme of this website, requires corporate and personal commitment, and developers seeking that level of commitment must understand the why as much as the how. We hope this article (as well as the rest of this website) has brought the whys closer.
In the comments, let us know if we missed an important algorithm or made a mistake.