
Integer Factorization Algorithms: A Comparative Analysis
Integer factorization consists of breaking down a composite number into its prime factors, a crucial aspect of cryptography, number theory, and computer science. Various integer factorization algorithms have been developed, each with strengths and limitations.

We evaluate each algorithm’s computational efficiency, provide examples and use cases, and showcase the algorithms using Python code.
1. Trial Division Algorithm
The Trial Division Algorithm is the simplest and most straightforward integer factorization algorithm. It involves sequentially dividing the number n by each integer less than its square root and testing if it is a factor. If a factor is found, the algorithm returns it, and if no factor is found, n is prime.
Using Python, the algorithm can be represented as:
import random
import math
import time
# Main function
# ---------------
def gcd(a, b):
while b != 0:
a, b = b, a % b
return a
# This function factorizes a large composite number N
# -------------------------------------------------
def factor(N):
for a in range(2, math.ceil(math.sqrt(N-1))):
if gcd(a, N) > 1:
print (str(a) + " is a factor of " + str(N))
return a
return 1
# TEST
#-----
start_time = time.time()
factor(9999973 * 9999991)
end_time = time.time()
print("Elpased time = " + str(end_time - start_time))
While the Trial Division Algorithm is easy to implement, it is computationally inefficient for large numbers since it has a time complexity of:
Factoring 9999973 * 9999991 consumes around 4 seconds on my laptop. We will use this number as a benchmark to compare the remaining algorithms.
2. Pollard’s Rho Algorithm
2.1 Example of Pollard’s Rho Algorithm
Pollard’s Rho Algorithm is a probabilistic algorithm for factoring composite integers. It is based on “random walks” on a cyclic group of integers modulo n. It’s particularly useful when dealing with large composite numbers that have at least one small prime factor.
import time
# Helper function
# -----------------
def f(x, n):
r = (x**2 + 1) % n
return r
# Brute force GCD
# ---------------
def gcd(a, b):
while b != 0:
a, b = b, a % b
return a
# Main function
# ---------------
def pollard_rho(n):
print ("Finding GCD of " + str(n))
x = 2
y = 2
d = 1
while d == 1:
x = f(x, n)
y = f(f(y, n), n)
d = gcd(abs(x - y), n)
if d == n:
return None
return d, n // d
# TEST
#------
start_time = time.time()
print (pollard_rho(9999973 * 9999991))
end_time = time.time()
print("Elpased time = " + str(end_time - start_time))
The Pollard’s Rho algorithm above takes about 0.003 seconds, an improvement of 1,333% over the trial division from the previous section, which takes around 4 seconds.
2.2 Pollard’s Rho Algorithm Breakdown
Here’s a breakdown of the algorithm:
The tortoise is represented by x.

And the hare is represented by y.

2.3 Pollard’s Rho Algorithm Complexity
The complexity of Pollard’s Rho Algorithm in Big O notation is typically expressed as:

Here’s why:

3. General Number Field Sieve Algorithm
The General Number Field Sieve (GNFS) algorithm is currently the fastest known algorithm for factoring large integers. It was first proposed by John Pollard in 1970 and later improved by Carl Pomerance and Richard Crandall in 1988. The algorithm finds smooth numbers in a large interval and then uses linear algebra to find the factors.
3.1 Description of General Number Field Sieve Algorithm
The GNFS algorithm is a two-stage algorithm. The first stage involves finding smooth numbers in a large interval. The second stage involves using linear algebra to find the factors of the factored integer.
In the first stage, the algorithm selects a large smoothness bound B and finds two integers, x and y, such that x2 = y2 (mod n), where n is the factored integer. The algorithm then constructs a polynomial of degree B using these two integers and uses sieving to find a set of B-smooth numbers. These B-smooth numbers are used in the second stage of the algorithm.
In the second stage, the algorithm constructs a matrix using the B-smooth numbers found in the first stage. The matrix has dimensions of (r+s) x r, where r is the number of prime factors of the smooth numbers and s is a parameter that depends on the size of the numbers being factored. The algorithm then uses Gaussian elimination to solve the matrix and find the factors of the factored integer.
3.2 Computational efficiency and limitations
The GNFS algorithm is currently the most efficient algorithm for factoring large integers. However, running requires a significant amount of memory and processing power. The time complexity of the algorithm is of the order of:
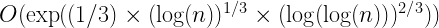
This means the algorithm is polynomial but still very slow for large integers.
3.3 Examples and use cases
The GNFS algorithm has been used to factor several large integers, including RSA-768, which was factored in 2009 using a distributed computing network. The algorithm has also been used to factor the largest known Fermat number, F12, which has 155 digits.
4. Comparison of Algorithms
Regarding integer factorization, there are several algorithms to choose from. The table below compares the computational efficiency and limitations of each algorithm.
| Algorithm | Computational Efficiency | Limitations |
|---|---|---|
| Trial division | 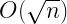 | Only efficient for small primes |
| Pollard’s Rho | | Limited to smaller factors |
| Quadratic Sieve |  | Limited to numbers with small factors |
| General Number Field Sieve |  | Requires a significant amount of memory and processing power |
4.1 Examples and use cases
The choice of algorithm depends on the size and structure of the integer being factored. For small primes, trial division is the most efficient algorithm. Pollard’s Rho and the Quadratic Sieve are efficient for larger integers but have limitations. The General Number Field Sieve is the most efficient algorithm for factoring large integers, but it requires significant memory and processing power.
5. Conclusion
In conclusion, integer factorization is a fundamental problem in computer science and has many practical applications, particularly in cryptography. Several algorithms are available for integer factorization, each with advantages and limitations. The choice of algorithm largely depends on the size of the number to be factored in and the available computing resources. It is important to choose the right algorithm to ensure efficient and timely factorization of large integers.
For small to medium-sized integers, Pollard’s Rho algorithm is recommended. For integers that are too large for trial division but too small for the GNFS, the Quadratic Sieve algorithm is recommended. For very large integers, the GNFS is the most efficient algorithm.
Research in integer factorization is ongoing to improve the efficiency of existing algorithms and develop new ones. Future directions in integer factorization research include:
- Improving the polynomial selection process in the GNFS to reduce the running time of the algorithm
- Developing new algorithms that are faster and more efficient than existing ones
- Exploring quantum algorithms for integer factorization
6. References
- A Monte Carlo Method for Factorization, J. M. Pollard, 1975
See Voinov, V. (2023) A simple enumerative polynomial-time algorithm for the prime factorization. CABJ 23(2), pp.1-6
Thanks, Vassily; I will have a look during the next revision of this article.
Pollard’s Rho Algorithm has a different logic.
Because if the numbers in the sequence were random, it would take enormous steps to find a number with a common divisor.
n=a*b = 37*47=1739
numbers_factors = (a-1)+(b-1) = 82
So there is 82 numbers:
37*2, 37*3, 37*4, …, 37*46
47*2, 47*3, …, 47*36
Average distance between factors = (n-2a)/numbers_factors = 20.3 (for n=1739)
So if we take really random numbers on the field it O(N) = O[(n-2a)/(2a-2)] = O (N^1/2)
The solution is that x1 = x*x+1 gives a polynomial that has many roots and has many fractions:
P(x) = (G(x)^2+1)^2+1 – (G(x)^2+1) = P0(x)*P1(x)…..Pn(x) where n=2*i
But Pollards has O(N^1/4) on average (that is one more mistake in your article) and is much more faster then Brute Force and Ferma methods
A huge part of number theory is based on factorisation. When factorisation is mentioned, prime factorisation immediately comes to mind. This means a lot of the algorithms in existence are majorly (if not entirely) focused on Prime factorisation.
My question is: Is there any algorithm or method on ground that specifically targets composite factorisation…i.e an algorithm that can derive all possible composite factors of a number, apart from trial division and the usual combination of prime factors to form composites.